A survey on datasets for fairness-aware machine learning
We overview real-world datasets (tabular data as the most common data representation) used for fairness-aware ML. We start our analysis by identifying relationships between the different attributes, particularly wrt. protected attributes and class attribute, using a Bayesian network. For a deeper understanding of bias in the datasets, we investigate interesting relationships using exploratory analysis.
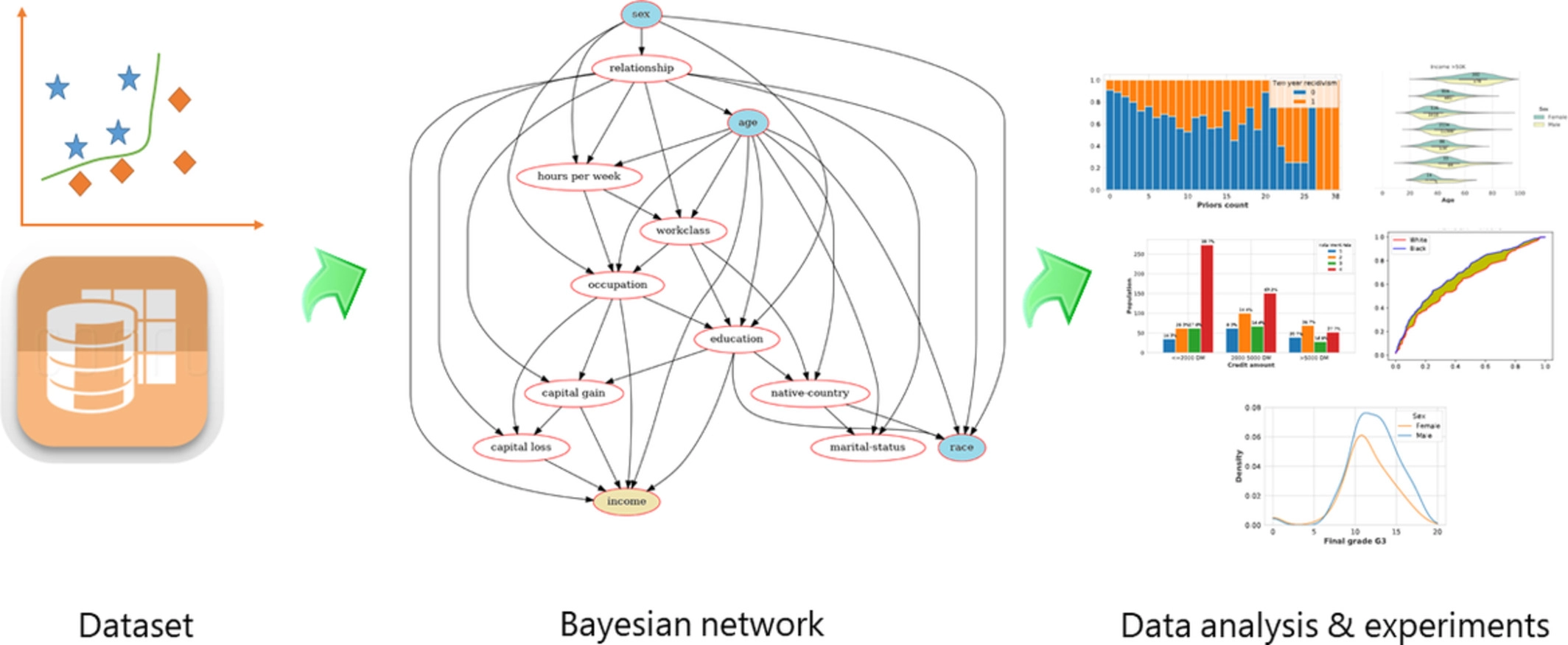
Tai Le Quy, Arjun Roy, Vasileios Iosifidis, Wenbin Zhang and Eirini Ntoutsi “A survey on datasetsfor fairness-aware machine learning”. 2022. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery. Wiley Periodicals, Inc. https://doi.org/10.1002/widm.1452